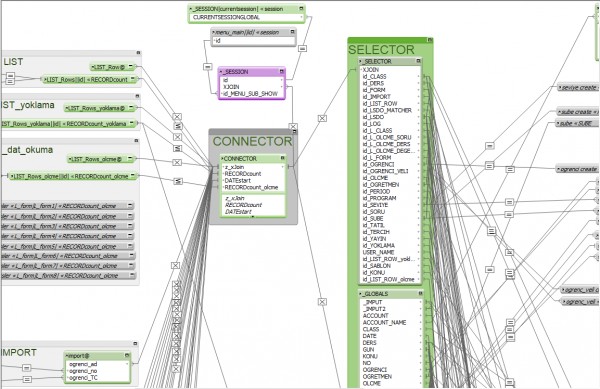
Ben kendi okulum için bir yönetim sistemi oluşturmaya çaışıyorum, proje büyüdükçe içinde kayboldum :) sonra selector connector modeli ile veritabanını yeniden oluşturdum. Şimdi de data seperation entegre ederek layout ve datayı birbirinden ayırmakla uğraşıyorum.
Birden çok kişinin çalıştığı ya da orta ve küçük bir projede Anchor Buoy modelini tercih ederdim.
Selector connectorda genelde Magic key ile oluşturulan kayıtların benchmarkta düşük sonuçlar elde ettiğini okumuştum. Dolayısı ile selector connector modelinin anchor buoy modelinin üzerine bir performans avantajının olmadığını söyleyebilirim. Fakat kodlamada ciddi avantaj sağladığını düşünüyorum. Bu modeli 2015 de icad eden olmasa da pazarlayan Tog Geist da bu modelin kapsamlı projeleri kolaylaştırmak amacı ile uygun olduğunu belirtmiş. Örneğin öğrencileri oluştururken bir kez oluşturduğum ilişki tablosu ile daha sonra defalarca farklı layot ve scriplerde öğrenciye bağlanmak için aynı ilişki tablosunu kullanabildim. Dahası daha önceye göre veritabanı şemasına da daha az bakar oldum. Eski haline göre çok daha derli toplu bir hale geldi diyebilirim.
Bu modelde temel olarak tüm layoutlar session tablosu üzerinden çalışır. Connector tablosu sizi tüm tablolara bağlar. Selector tablosu içinde oluşturacağınız global alanlar ile istediğiniz veriye bağlanırsınız yada magic key yöntemi ile kayıt oluşturabilirsiniz. Ekran görüntüsünde gördüğünüz üzere ben selector tablosunu klonlayarak bir de Globals tablosu oluşturdum ve layout üzerinde kullandığım globalleri burada topladım yani front end de kullandığım bağlantıları mümkün olduğunca global tablosundan back end de (yani layoutta kullanmadığım) ilişkilere ise selectordan bağlanmaya çalıştım
Çoklu kullanıcı olan uygulamalarda güncelleme yapmak gerekecek ise Data seperation kullanılması gerektiğini düşünüyorum. Data seperation yaparken sistem kullanıcılarını oluştuturken ve giriş yaparken filemakerın kullancı sistemindense kendi kullanıcı sisteminizi oluşturmanız bu modelde karşılaşabileceğiniz en önemli güncelleme sorununu çözecektir.